
Observability-Driven QA: Using Logs, Traces, and Metrics to Find Defects Faster
In today's fast-paced digital landscape, ensuring the quality of software applications is more critical than ever. As organizations increasingly adopt cloud-native architectures and microservices, the complexity of systems has grown exponentially. This complexity necessitates a shift in how we approach quality assurance (QA). Enter observability-driven QA, a methodology that leverages logs, traces, and metrics to enhance testing processes and identify defects more efficiently. By integrating observability into QA practices, teams can gain deeper insights into system behavior, enabling them to detect issues proactively and improve overall software quality.
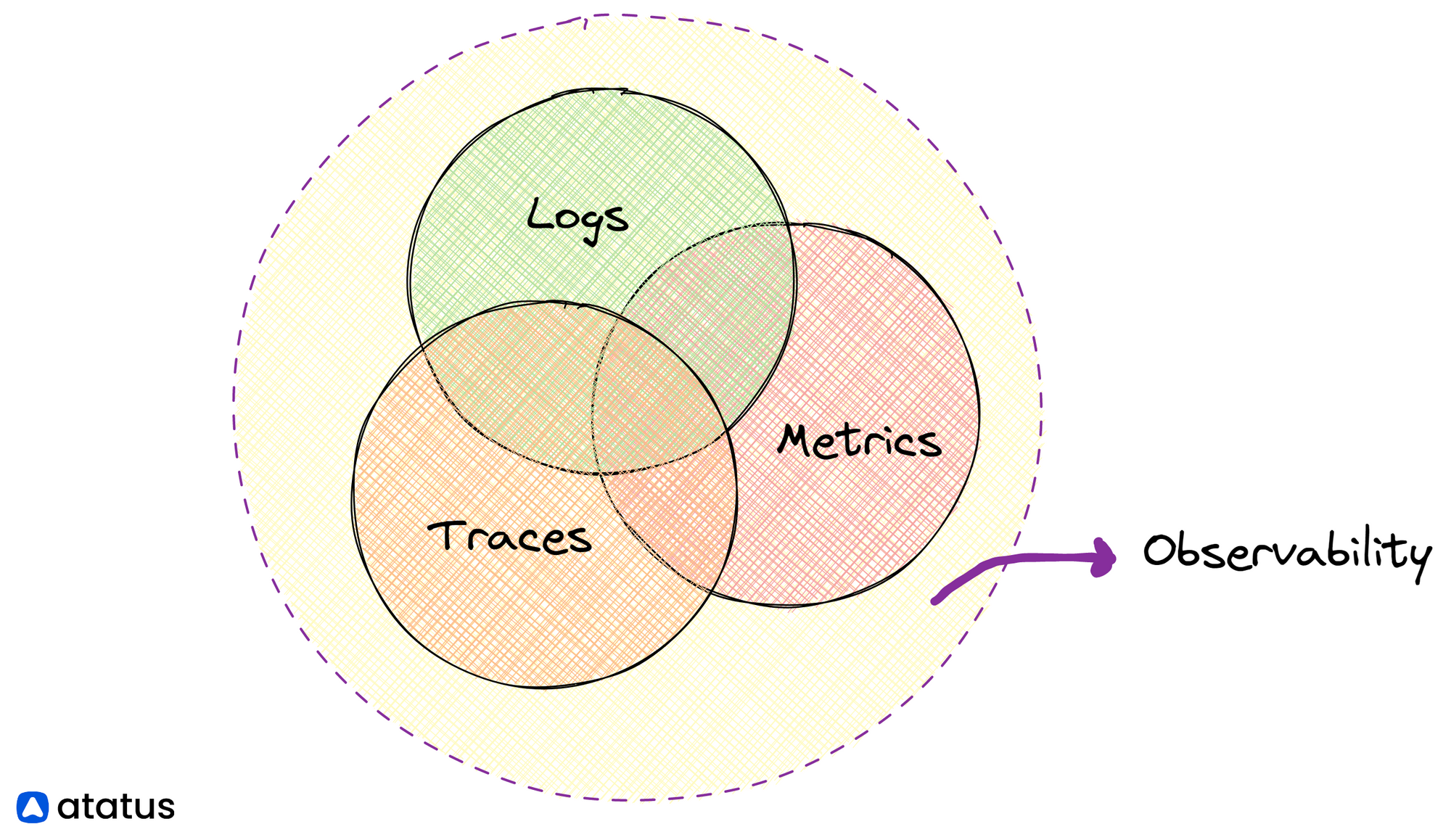
Understanding Observability in QA
Observability refers to the ability to understand a system's internal state based on the data it generates. In the context of QA, observability allows teams to monitor applications in real-time, providing visibility into their performance and behavior. This visibility is crucial for identifying defects and understanding their root causes.
The Three Pillars of Observability
Observability is built upon three foundational pillars: logs, metrics, and traces. Each of these components plays a vital role in providing insights into system behavior.
-
Logs: These are timestamped records of events that occur within an application. Logs capture detailed information about system behavior, including errors, transactions, and user interactions. They serve as a primary source of truth during troubleshooting, helping teams understand what went wrong and why.
-
Metrics: Metrics provide quantitative data about system performance over time. They track key performance indicators (KPIs) such as CPU usage, memory consumption, and request latency. By analyzing metrics, teams can identify trends, monitor service level agreements (SLAs), and make informed decisions about resource allocation.
-
Traces: Tracing involves tracking the flow of requests through various services in a distributed system. Traces provide a comprehensive view of how different components interact, allowing teams to pinpoint latency issues and identify bottlenecks in the system.
Together, these pillars create a holistic view of system behavior, enabling teams to detect and resolve issues more effectively.
The Role of Logs in Observability-Driven QA
Logs are often the first line of defense when it comes to identifying defects in software applications. They provide granular insights into system events, making them invaluable for debugging and troubleshooting.
Benefits of Log-Based Testing
Log-based testing involves analyzing logs to identify defects and improve software quality. This approach offers several advantages:
-
Detailed Context: Logs provide rich context about system behavior, allowing teams to understand the circumstances surrounding an issue. This context is crucial for diagnosing problems and implementing effective solutions.
-
Historical Data: Logs serve as a historical record of system events, enabling teams to analyze trends over time. By examining historical logs, teams can identify recurring issues and address them proactively.
-
Real-Time Monitoring: With log aggregation tools, teams can monitor logs in real-time, receiving alerts for anomalies or errors as they occur. This proactive approach allows teams to address issues before they impact end users.
Implementing Log-Based Testing
To effectively implement log-based testing, teams should consider the following best practices:
-
Centralized Logging: Use a centralized logging solution to aggregate logs from various services and components. This approach simplifies log management and enables comprehensive analysis.
-
Structured Logging: Adopt structured logging practices to ensure logs are easily parseable and searchable. Structured logs facilitate better analysis and correlation with other observability data.
-
Log Retention Policies: Establish log retention policies to manage storage costs while retaining essential data for analysis. This ensures that teams have access to historical logs when needed.
Tracing-Led Debugging: Enhancing Issue Resolution
Tracing-led debugging is a powerful technique that leverages distributed tracing to identify and resolve defects in complex systems. By following the path of requests through various services, teams can gain insights into how different components interact and where issues may arise.
Advantages of Tracing in QA
-
End-to-End Visibility: Tracing provides a complete view of how requests flow through the system, allowing teams to identify bottlenecks and latency issues. This visibility is especially valuable in microservices architectures, where requests may traverse multiple services.
-
Root Cause Analysis: By analyzing traces, teams can pinpoint the exact location of failures and understand the sequence of events leading to an issue. This information is crucial for effective root cause analysis.
-
Performance Optimization: Tracing data can reveal performance bottlenecks, enabling teams to optimize their applications for better user experiences. By addressing these bottlenecks, organizations can improve overall system performance.
Best Practices for Tracing-Led Debugging
To maximize the benefits of tracing-led debugging, teams should follow these best practices:
-
Instrument All Services: Ensure that all services in the architecture are instrumented for tracing. This comprehensive instrumentation provides a complete view of request flows.
-
Use Trace Context Propagation: Implement trace context propagation to maintain trace information as requests move between services. This ensures that traces remain intact and provide accurate insights.
-
Visualize Traces: Utilize visualization tools to represent traces graphically. Visualizations can help teams quickly identify bottlenecks and understand the relationships between different components.
Metrics-Driven Testing: Monitoring Performance
Metrics play a crucial role in observability-driven QA by providing quantitative insights into system performance. By monitoring key metrics, teams can assess the health of their applications and identify potential issues before they escalate.
Importance of Metrics in QA
-
Performance Monitoring: Metrics allow teams to monitor application performance in real-time. By tracking metrics such as response times and error rates, teams can quickly identify performance degradation.
-
Capacity Planning: Metrics provide valuable data for capacity planning and resource allocation. By analyzing usage patterns, teams can make informed decisions about scaling their infrastructure.
-
SLA/SLO Awareness: Metrics help teams ensure compliance with service level agreements (SLAs) and service level objectives (SLOs). By monitoring relevant metrics, teams can proactively address issues that may impact service quality.
Implementing Metrics-Driven Testing
To effectively implement metrics-driven testing, teams should consider the following strategies:
-
Define Key Metrics: Identify key metrics that align with business objectives and user expectations. Focus on metrics that provide actionable insights into system performance.
-
Set Thresholds and Alerts: Establish thresholds for critical metrics and configure alerts to notify teams when thresholds are breached. This proactive approach enables teams to address issues before they impact users.
-
Regularly Review Metrics: Conduct regular reviews of metrics to identify trends and patterns. This analysis can help teams uncover potential issues and optimize performance.
Shift-Right Testing: Embracing Observability
Shift-right testing is an approach that emphasizes testing in production environments. By leveraging observability data, teams can gain insights into real user experiences and identify defects that may not be apparent in traditional testing environments.
Benefits of Shift-Right Testing
-
Real-World Insights: Shift-right testing allows teams to gather data from real users, providing insights into how applications perform in production. This data is invaluable for identifying defects that may not surface during pre-production testing.
-
Continuous Improvement: By continuously monitoring applications in production, teams can identify areas for improvement and implement changes iteratively. This approach fosters a culture of continuous improvement.
-
Enhanced User Experience: By addressing defects identified through shift-right testing, teams can enhance the overall user experience. This focus on user satisfaction is critical for maintaining customer loyalty.
Implementing Shift-Right Testing
To effectively implement shift-right testing, teams should consider the following practices:
-
Monitor User Interactions: Utilize observability tools to monitor user interactions and gather data on application performance. This data can help teams identify defects and areas for improvement.
-
Conduct A/B Testing: Implement A/B testing to compare different versions of an application and gather user feedback. This approach allows teams to make data-driven decisions about feature releases.
-
Iterate Based on Feedback: Use feedback from shift-right testing to inform development and testing processes. This iterative approach ensures that teams are continuously improving their applications.
Error Budget Monitoring: Balancing Quality and Speed
Error budget monitoring is a practice that helps teams balance the need for speed with the importance of quality. By defining an error budget, teams can prioritize their efforts and make informed decisions about feature releases.
Understanding Error Budgets
An error budget represents the acceptable level of errors or downtime for a service. By defining this budget, teams can make data-driven decisions about when to prioritize bug fixes versus new feature development.
Benefits of Error Budget Monitoring
-
Prioritization: Error budget monitoring helps teams prioritize their efforts based on the current state of the application. If the error budget is nearing its limit, teams can focus on addressing defects before releasing new features.
-
Improved Collaboration: By establishing a shared understanding of the error budget, teams can collaborate more effectively. This alignment fosters a culture of accountability and encourages teams to work together to maintain quality.
-
Data-Driven Decision Making: Error budget monitoring enables teams to make informed decisions about feature releases and bug fixes. This data-driven approach minimizes the risk of introducing new defects.
Implementing Error Budget Monitoring
To effectively implement error budget monitoring, teams should consider the following strategies:
-
Define Error Budgets: Establish clear error budgets based on business objectives and user expectations. This definition provides a framework for prioritizing efforts.
-
Monitor Error Rates: Continuously monitor error rates and compare them to the defined error budget. This monitoring allows teams to identify when they need to shift their focus.
-
Communicate Across Teams: Foster open communication about error budgets across teams. This transparency ensures that everyone is aligned and working towards common goals.
SLA/SLO-Aware QA: Ensuring Compliance
SLA/SLO-aware QA involves aligning testing practices with service level agreements (SLAs) and service level objectives (SLOs). By incorporating observability data into QA processes, teams can ensure compliance with these agreements and deliver high-quality software.
Importance of SLA/SLO Awareness
-
Customer Satisfaction: Meeting SLAs and SLOs is critical for maintaining customer satisfaction. By aligning QA practices with these agreements, teams can ensure that applications meet user expectations.
-
Risk Mitigation: SLA/SLO-aware QA helps teams identify potential risks and address them proactively. This approach minimizes the likelihood of service disruptions and enhances overall reliability.
-
Continuous Improvement: By monitoring compliance with SLAs and SLOs, teams can identify areas for improvement and implement changes iteratively. This focus on continuous improvement fosters a culture of quality.
Implementing SLA/SLO-Aware QA
To effectively implement SLA/SLO-aware QA, teams should consider the following practices:
-
Define SLAs and SLOs: Establish clear SLAs and SLOs that align with business objectives and user expectations. This definition provides a framework for measuring compliance.
-
Monitor Compliance: Continuously monitor compliance with SLAs and SLOs using observability data. This monitoring allows teams to identify when they need to take corrective action.
-
Communicate Expectations: Foster open communication about SLAs and SLOs across teams. This transparency ensures that everyone is aligned and working towards common goals.
Telemetry-Driven Test Design: Enhancing Test Effectiveness
Telemetry-driven test design involves leveraging observability data to inform testing strategies and improve test effectiveness. By incorporating telemetry into test design, teams can create more targeted and relevant tests.
Benefits of Telemetry-Driven Test Design
-
Targeted Testing: Telemetry data allows teams to identify areas of the application that require more rigorous testing. This targeted approach ensures that testing efforts are focused on high-risk areas.
-
Improved Test Coverage: By analyzing telemetry data, teams can identify gaps in test coverage and address them proactively. This improvement enhances overall test effectiveness.
-
Data-Driven Decisions: Telemetry-driven test design enables teams to make data-driven decisions about testing strategies. This approach minimizes the risk of overlooking critical areas.
Implementing Telemetry-Driven Test Design
To effectively implement telemetry-driven test design, teams should consider the following strategies:
-
Analyze Telemetry Data: Continuously analyze telemetry data to identify areas that require more rigorous testing. This analysis informs test design and prioritization.
-
Collaborate Across Teams: Foster collaboration between development and QA teams to ensure that telemetry data is used effectively in test design. This collaboration enhances overall test effectiveness.
-
Iterate Based on Feedback: Use feedback from telemetry analysis to inform testing strategies and improve test design iteratively. This iterative approach ensures that teams are continuously improving their testing practices.
Conclusion
Observability-driven QA represents a paradigm shift in how organizations approach software quality assurance. By leveraging logs, traces, and metrics, teams can gain deeper insights into system behavior, enabling them to detect defects faster and improve overall software quality. As organizations continue to embrace cloud-native architectures and microservices, the importance of observability in QA will only grow. By adopting observability-driven practices, teams can enhance their testing processes, ensure compliance with SLAs and SLOs, and ultimately deliver high-quality software that meets user expectations. Embracing this approach will not only improve software quality but also foster a culture of continuous improvement and collaboration within teams.





